Variational Bayesian methods
Variational Bayesian methods, also called 'ensemble learning', are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables (usually termed "data") as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As is typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods can provide an analytical approximation to the posterior probability of the unobserved variables, and also to derive a lower bound for the marginal likelihood (sometimes called the "evidence") of several models (i.e. the marginal probability of the data given the model, with marginalization performed over unobserved variables), with a view to performing model selection. It is an alternative to Monte Carlo sampling methods for taking a fully Bayesian approach to statistical inference over complex distributions that are difficult to directly evaluate or sample from.
Variational Bayes can be seen as an extension of the EM (expectation-maximization) algorithm from maximum a posteriori estimation (MAP estimation) of the single most probable value of each parameter to fully Bayesian estimation which computes(an approximation to) the entire posterior distribution of the parameters and latent variables.
Contents |
Mathematical derivation
In variational inference, the posterior distribution over a set of unobserved variables 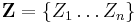 given some data
given some data 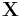 is approximated by a variational distribution,
is approximated by a variational distribution, 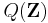 :
:
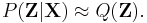
The distribution is restricted to belong to a family of distributions of simpler form than 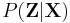 , selected with the intention of making similar to the true posterior, . The lack of similarity is measured in terms of a dissimilarity function
, selected with the intention of making similar to the true posterior, . The lack of similarity is measured in terms of a dissimilarity function 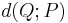 and hence inference is performed by selecting the distribution that minimizes . One choice of dissimilarity function that makes this minimization tractable is the Kullback–Leibler divergence (KL divergence) of P from Q, defined as
and hence inference is performed by selecting the distribution that minimizes . One choice of dissimilarity function that makes this minimization tractable is the Kullback–Leibler divergence (KL divergence) of P from Q, defined as
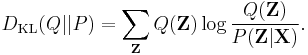
This can be written as
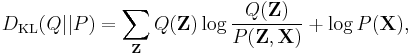
or
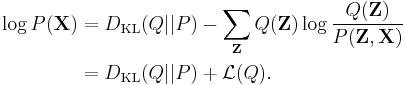
As the so-called log evidence 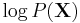 is fixed with respect to
is fixed with respect to 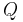 , maximising the final term
, maximising the final term 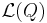 minimizes the KL divergence of
minimizes the KL divergence of 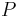 from . By appropriate choice of , becomes tractable to compute and to maximize. Hence we have both an analytical approximation for the posterior , and a lower bound for the evidence . The lower bound is known as the (negative) variational free energy because it can also be expressed as an "energy"
from . By appropriate choice of , becomes tractable to compute and to maximize. Hence we have both an analytical approximation for the posterior , and a lower bound for the evidence . The lower bound is known as the (negative) variational free energy because it can also be expressed as an "energy" ![\operatorname{E}_{Q}[\log P(\mathbf{Z},\mathbf{X})]](/2012-wikipedia_en_all_nopic_01_2012/I/91e09782bd98ca4900ef928f3f4e39dc.png) plus the entropy of .
plus the entropy of .
In practice
The variational distribution is usually assumed to factorize over some partition of the latent variables, i.e. for some partition of the latent variables 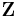 into
into  ,
,
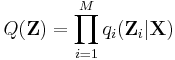
It can be shown using the calculus of variations (hence the name "variational Bayes") that the "best" distribution 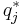 for each of the factors
for each of the factors 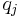 (in terms of the distribution minimizing the KL divergence, as described above) can be expressed as:
(in terms of the distribution minimizing the KL divergence, as described above) can be expressed as:
![q_j^{*}(\mathbf{Z}_j|\mathbf{X}) = \frac{e^{\operatorname{E}_{i \neq j} [\ln p(\mathbf{Z}, \mathbf{X})]}}{\int e^{\operatorname{E}_{i \neq j} [\ln p(\mathbf{Z}, \mathbf{X})]}\, d\mathbf{Z}_j}](/2012-wikipedia_en_all_nopic_01_2012/I/cfb0f60f88f2bb741b122d64ddf71da7.png)
where ![\operatorname{E}_{i \neq j} [\ln p(\mathbf{Z}, \mathbf{X})]](/2012-wikipedia_en_all_nopic_01_2012/I/4c448c7eadd2967b584341e8535376cb.png) is the expectation of the joint probability of the data and latent variables, taken over all variables not in the partition.
is the expectation of the joint probability of the data and latent variables, taken over all variables not in the partition.
In practice, we usually work in terms of logarithms, i.e.:
![\ln q_j^{*}(\mathbf{Z}_j|\mathbf{X}) = \operatorname{E}_{i \neq j} [\ln p(\mathbf{Z}, \mathbf{X})] %2B \text{constant}](/2012-wikipedia_en_all_nopic_01_2012/I/00dbc23370e784e3e268548d576341c8.png)
The constant in the above expression is related to the normalizing constant (the denominator in the expression above for ) and is usually reinstated by inspection, as the rest of the expression can usually be recognized as being a known type of distribution (e.g. Gaussian, gamma, etc.).
Using the properties of expectations, the expression can usually be simplified into a function of the fixed hyperparameters of the prior distributions over the latent variables and of expectations (and sometimes higher moments such as the variance) of latent variables not in the current partition (i.e. latent variables not included in 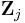 ). This creates circular dependencies between the parameters of the distributions over variables in one partition and the expectations of variables in the other partitions. This naturally suggests an iterative algorithm, much like EM (the expectation-maximization algorithm), in which the expectations (and possibly higher moments) of the latent variables are initialized in some fashion (perhaps randomly), and then the parameters of each distribution are computed in turn using the current values of the expectations, after which the expectation of the newly computed distribution is set appropriately according to the computed parameters. An algorithm of this sort is guaranteed to converge.[1] Furthermore, if the distributions in question are part of the exponential family, which is usually the case, convergence will be to a global maximum, since the exponential family is convex.[2]
). This creates circular dependencies between the parameters of the distributions over variables in one partition and the expectations of variables in the other partitions. This naturally suggests an iterative algorithm, much like EM (the expectation-maximization algorithm), in which the expectations (and possibly higher moments) of the latent variables are initialized in some fashion (perhaps randomly), and then the parameters of each distribution are computed in turn using the current values of the expectations, after which the expectation of the newly computed distribution is set appropriately according to the computed parameters. An algorithm of this sort is guaranteed to converge.[1] Furthermore, if the distributions in question are part of the exponential family, which is usually the case, convergence will be to a global maximum, since the exponential family is convex.[2]
In other words, for each of the partitions of variables, by simplifying the expression for the distribution over the partition's variables and examining the distribution's functional dependency on the variables in question, the family of the distribution can usually be determined (which in turn determines the value of the constant). The formula for the distribution's parameters will be expressed in terms of the prior distributions' hyperparameters (which are known constants), but also in terms of expectations of functions of variables in other partitions. Usually these expectations can be simplified into functions of expectations of the variables themselves (i.e. the means); sometimes expectations of squared variables (which can be related to the variance of the variables), or expectations of higher powers (i.e. higher moments) also appear. In most cases, the other variables' distributions will be from known families, and the formulas for the relevant expectations can be looked up. However, those formulas depend on those distributions' parameters, which depend in turn on the expectations about other variables. The result is that the formulas for the parameters of each variable's distributions can be expressed as a series of equations with mutual, nonlinear dependencies among the variables. Usually, it is not possible to solve this system of equations directly. However, as described above, the dependencies suggest a simple iterative algorithm, which in most cases is guaranteed to converge. An example will make this process clearer.
A simple example
Imagine a simple Bayesian model consisting of a single node with a Gaussian distribution, with unknown mean and precision (or equivalently, an unknown variance, since the precision is the reciprocal of the variance).[3]
We place conjugate prior distributions on the unknown mean and variance, i.e. the mean also follows a Gaussian distribution while the precision follows a gamma distribution. In other words:
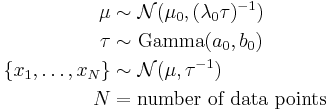
We are given 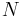 data points
data points 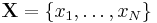 and our goal is to infer the posterior distribution
and our goal is to infer the posterior distribution 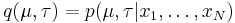 of the parameters
of the parameters 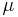 and
and 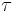 .
.
The hyperparameters 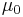 ,
, 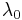 ,
, 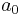 and
and 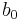 are fixed, given values. They can be set to small positive numbers to give broad prior distributions indicating ignorance about the prior distributions of and .
are fixed, given values. They can be set to small positive numbers to give broad prior distributions indicating ignorance about the prior distributions of and .
The joint probability of all variables can be rewritten as
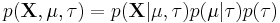
where the individual factors are
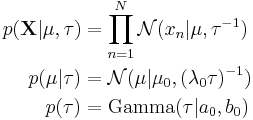
where
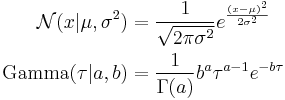
Assume that 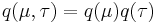 , i.e. that the posterior distribution factorizes into independent factors for and . This type of assumption underlies the variational Bayesian method. The true posterior distribution does not in fact factor this way (in fact, in this simple case, it is known to be a Gaussian-gamma distribution), and hence the result we obtain will be an approximation.
, i.e. that the posterior distribution factorizes into independent factors for and . This type of assumption underlies the variational Bayesian method. The true posterior distribution does not in fact factor this way (in fact, in this simple case, it is known to be a Gaussian-gamma distribution), and hence the result we obtain will be an approximation.
Then
![\begin{align}
\ln q_\mu^*(\mu) &= \operatorname{E}_{\tau}[\ln p(\mathbf{X}|\mu,\tau) %2B \ln p(\mu|\tau)] %2B \text{constant} \\
&= - \frac{\operatorname{E}[\tau]}{2} \{ \lambda_0(\mu-\mu_0)^2 %2B \sum_{n=1}^N (x_n-\mu)^2 \} %2B \text{constant}
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/dbe45559028233d18900f423a83fa260.png)
Note that the term ![\operatorname{E}_{\tau}[\ln p(\tau)]](/2012-wikipedia_en_all_nopic_01_2012/I/5b4004b9a41ebc8f7fe9acac5940d0df.png) will be a function solely of and and hence is constant with respect to ; thus it has been absorbed into the constant term at the end. By expanding the squares inside of the braces, separating out and grouping the terms involving and
will be a function solely of and and hence is constant with respect to ; thus it has been absorbed into the constant term at the end. By expanding the squares inside of the braces, separating out and grouping the terms involving and 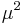 and completing the square over , we see that
and completing the square over , we see that 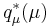 is a Gaussian distribution
is a Gaussian distribution 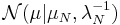 where we have defined:
where we have defined:
![\begin{align}
\mu_N &= \frac{\lambda_0 \mu_0 %2B N \bar{x}}{\lambda_0 %2B N} \\
\lambda_N &= (\lambda_0 %2B N) \operatorname{E}[\tau]
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/3cb23c27d44075ea90707d0a15144b6b.png)
Similarly,
![\begin{align}
\ln q_\tau^*(\tau) &= \operatorname{E}_{\mu}[\ln p(\mathbf{X}|\mu,\tau) %2B \ln p(\mu|\tau)] %2B \ln p(\tau) %2B \text{constant} \\
&= (a_0 - 1) \ln \tau - b_0 \tau %2B \frac{N}{2} \ln \tau - \frac{\tau}{2} \operatorname{E}_\mu [\sum_{n=1}^N (x_n-\mu)^2 %2B \lambda_0(\mu - \mu_0)^2] %2B \text{constant}
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/4b81bd79a683f18937afa7842b580c29.png)
Exponentiating both sides, we can see that 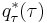 is a gamma distribution
is a gamma distribution 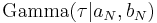 where we have defined
where we have defined
![\begin{align}
a_N &= a_0 %2B \frac{N%2B1}{2} \\
b_N &= b_0 %2B \frac{1}{2} \operatorname{E}_\mu \left[\sum_{n=1}^N (x_n-\mu)^2 %2B \lambda_0(\mu - \mu_0)^2\right]
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/e497a25513d40fd90f79d5694e5a3fc6.png)
In each case, the parameters for the distribution over one of the variables depend on expectations taken with respect to the other variable. The formulas for the expectations of moments of the Gaussian and gamma distributions are well-known, but depend on the parameters. Hence the formulas for each distribution's parameters depend on the other distribution's parameters. This naturally suggests an EM-like algorithm where we first initialize the parameters to some values (perhaps the values of the hyperparameters of the corresponding prior distributions) and iterate, computing new values for each set of parameters using the current values of the other parameters. This is guaranteed to converge to a local maximum, and since both posterior distributions are in the exponential family, this local maximum will be a global maximum.
Note also that the posterior distributions have the same form as the corresponding prior distributions. We did not assume this; the only assumption we made was that the distributions factorize, and the form of the distributions followed naturally. It turns out (see below) that the fact that the posterior distributions have the same form as the prior distributions is not a coincidence, but a general result whenever the prior distributions are members of the exponential family, which is the case for most of the standard distributions.
A more complex example
Imagine a Bayesian Gaussian mixture model described as follows:
![\begin{align}
\mathbf{\pi} & \sim \operatorname{SymDir}(K, \alpha_0) \\
\mathbf{\Lambda}_{i=1 \dots K} & \sim \mathcal{W}(\mathbf{W}_0, \nu_0) \\
\mathbf{\mu}_{i=1 \dots K} & \sim \mathcal{N}(\mathbf{\mu}_0, (\beta_0 \mathbf{\Lambda}_i)^{-1}) \\
\mathbf{z}[i = 1 \dots N] & \sim \operatorname{Mult}(1, \mathbf{\pi}) \\
\mathbf{x}_{i=1 \dots N} & \sim \mathcal{N}(\mathbf{\mu}_{z_i}, {\mathbf{\Lambda}_{z_i}}^{-1}) \\
K &= \text{number of mixing components} \\
N &= \text{number of data points}
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/8db154eb0e56ed7064ea37b8a27820f7.png)
Note:
- SymDir() is the symmetric Dirichlet distribution of dimension
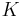 , with the hyperparameter for each component set to
, with the hyperparameter for each component set to 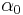 . The Dirichlet distribution is the conjugate prior of the categorical distribution or multinomial distribution.
. The Dirichlet distribution is the conjugate prior of the categorical distribution or multinomial distribution. 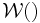 is the Wishart distribution, which is the conjugate prior of the precision matrix (inverse covariance matrix) for a multivariate Gaussian distribution.
is the Wishart distribution, which is the conjugate prior of the precision matrix (inverse covariance matrix) for a multivariate Gaussian distribution.- Mult() is a multinomial distribution over a single observation. The state space is a "one-of-K" representation, i.e. a -dimensional vector in which one of the elements is 1 (specifying the identity of the observation) and all other elements are 0.
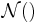 is the Gaussian distribution, in this case specifically the multivariate Gaussian distribution.
is the Gaussian distribution, in this case specifically the multivariate Gaussian distribution.
The interpretation of the above variables is as follows:
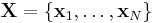 is the set of data points, each of which is a -dimensional vector distributed according to a multivariate Gaussian distribution.
is the set of data points, each of which is a -dimensional vector distributed according to a multivariate Gaussian distribution.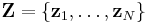 is a set of latent variables, one per data point, specifying which mixture component the corresponding data point belongs to, using a "one-of-K" vector representation with components
is a set of latent variables, one per data point, specifying which mixture component the corresponding data point belongs to, using a "one-of-K" vector representation with components 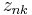 for
for 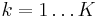 , as described above.
, as described above.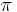 is the mixing proportions for the mixture components.
is the mixing proportions for the mixture components.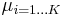 and
and 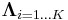 specify the parameters (mean and precision) associated with each mixture component.
specify the parameters (mean and precision) associated with each mixture component.
The joint probability of all variables can be rewritten as
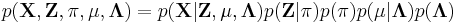
where the individual factors are
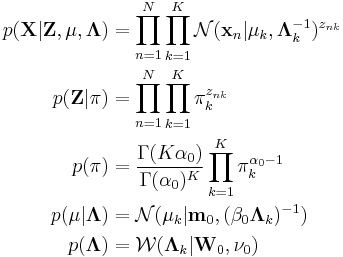
where
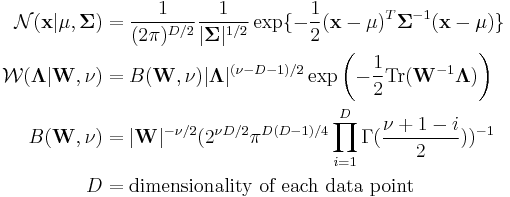
Assume that 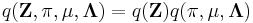 .
.
Then
![\begin{align}
\ln q^*(\mathbf{Z}) &= \operatorname{E}_{\mathbf{\pi},\mathbf{\mu},\mathbf{\Lambda}}[\ln p(\mathbf{X},\mathbf{Z},\mathbf{\pi},\mathbf{\mu},\mathbf{\Lambda})] %2B \text{constant} \\
&= \operatorname{E}_{\mathbf{\pi}}[\ln p(\mathbf{Z}|\mathbf{\pi})] %2B \operatorname{E}_{\mathbf{\mu},\mathbf{\Lambda}}[\ln p(\mathbf{X}|\mathbf{Z},\mathbf{\mu},\mathbf{\Lambda})] %2B \text{constant} \\
&= \sum_{n=1}^N \sum_{k=1}^K z_{nk} \ln \rho_{nk} %2B \text{constant}
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/9a463499e497a5ecca11aaaeaece2272.png)
where we have defined
![\ln \rho_{nk} = \operatorname{E}[\ln \pi_k] %2B \frac{1}{2} \operatorname{E}[\ln |\mathbf{\Lambda}_k|] - \frac{D}{2} \ln(2\pi) - \frac{1}{2} \operatorname{E}_{\mathbf{\mu}_k,\mathbf{\Lambda}_k} [(\mathbf{x}_n - \mathbf{\mu}_k)^T \mathbf{\Lambda}_k (\mathbf{x}_n - \mathbf{\mu}_k)]](/2012-wikipedia_en_all_nopic_01_2012/I/05bc9c890680d1856e71d14540695331.png)
Exponentiating both sides of the formula for 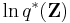 yields
yields
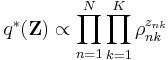
Requiring that this be normalized ends up requiring that the 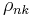 sum to 1 over all values of
sum to 1 over all values of  , yielding
, yielding
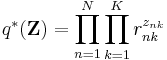
where
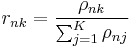
In other words, 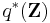 is a product of single-observation multinomial distributions, and factors over each individual
is a product of single-observation multinomial distributions, and factors over each individual 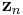 , which is distributed as a single-observation multinomial distribution with parameters
, which is distributed as a single-observation multinomial distribution with parameters 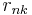 for .
for .
Furthermore, we note that
![\operatorname{E}[z_{nk}] = r_{nk} \,](/2012-wikipedia_en_all_nopic_01_2012/I/26473967fdc265955da739e2b50bd42c.png)
which is a standard result for categorical distributions.
Now, considering the factor 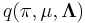 , note that it automatically factors into
, note that it automatically factors into 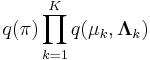 due to the structure of the graphical model defining our Gaussian mixture model, which is specified above.
due to the structure of the graphical model defining our Gaussian mixture model, which is specified above.
Then,
![\begin{align}
\ln q^*(\mathbf{\pi}) &= \ln p(\mathbf{\pi}) %2B \operatorname{E}_{\mathbf{Z}}[\ln p(\mathbf{Z}|\mathbf{\pi})] %2B \text{constant} \\
&= (\alpha_0 - 1) \sum_{k=1}^K \ln \pi_k %2B \sum_{n=1}^N \sum_{k=1}^K r_{nk} \ln \pi_k %2B \text{constant}
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/8ca590826632961e1633dffd6bcd8301.png)
Taking the exponential of both sides, we recognize 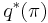 as a Dirichlet distribution
as a Dirichlet distribution
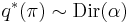
where
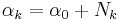
where
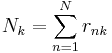
Finally
![\ln q^*(\mathbf{\mu}_k,\mathbf{\Lambda}_k) = \ln p(\mathbf{\mu}_k,\mathbf{\Lambda}_k) %2B \sum_{n=1}^N \operatorname{E}[z_{nk}] \ln \mathcal{N}(\mathbf{x}_n|\mathbf{\mu}_k,\mathbf{\Lambda}_k^{-1}) %2B \text{constant}](/2012-wikipedia_en_all_nopic_01_2012/I/81361639ff4f739654d79161c773dd80.png)
Grouping and reading off terms involving 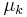 and
and 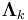 , the result is a Gaussian-Wishart distribution given by
, the result is a Gaussian-Wishart distribution given by
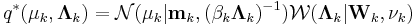
given the definitions
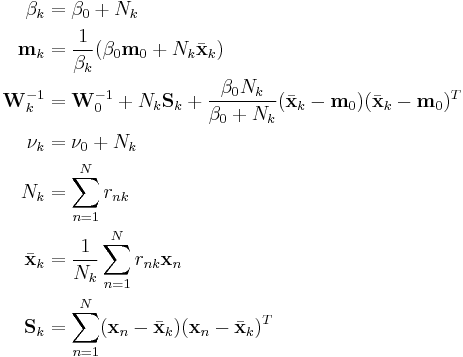
Finally, notice that these functions require the values of , which make use of , which is defined in turn based on ![\operatorname{E}[\ln \pi_k]](/2012-wikipedia_en_all_nopic_01_2012/I/4116da6fdfd154b6be7557b1dcbfa29f.png) ,
, ![\operatorname{E}[\ln |\mathbf{\Lambda}_k|]](/2012-wikipedia_en_all_nopic_01_2012/I/2d8099d0c3e0c4bbbc051e1a280ac51d.png) , and
, and ![\operatorname{E}_{\mathbf{\mu}_k,\mathbf{\Lambda}_k} [(\mathbf{x}_n - \mathbf{\mu}_k)^T \mathbf{\Lambda}_k (\mathbf{x}_n - \mathbf{\mu}_k)]](/2012-wikipedia_en_all_nopic_01_2012/I/709593629e3ee4e7293cf3fe0c6f5243.png) . Now that we have determined the distributions over which these expectations are taken, we can derive formulas for them:
. Now that we have determined the distributions over which these expectations are taken, we can derive formulas for them:
![\begin{array}{rcccl}
\operatorname{E}_{\mathbf{\mu}_k,\mathbf{\Lambda}_k} [(\mathbf{x}_n - \mathbf{\mu}_k)^T \mathbf{\Lambda}_k (\mathbf{x}_n - \mathbf{\mu}_k)] &&&=& D\beta_k^{-1} %2B \nu_k (\mathbf{x}_n - \mathbf{m}_k)^T \mathbf{W}_k (\mathbf{x}_n - \mathbf{m}_k) \\
\ln {\tilde{\Lambda}}_k &\equiv& \operatorname{E}[\ln |\mathbf{\Lambda}_k|] &=& \sum_{i=1}^D \psi \left(\frac{\nu_k %2B 1 - i}{2}\right) %2B D \ln 2 %2B \ln |\mathbf{\Lambda}_k| \\
\ln {\tilde{\pi}}_k &\equiv& \operatorname{E}\left[\ln |\pi_k|\right] &=& \psi(\alpha_k) - \psi\left(\sum{i=1}^K \alpha_i\right)
\end{array}](/2012-wikipedia_en_all_nopic_01_2012/I/1c3b750b14279f46bc3b11abdd4ad90b.png)
These results lead to
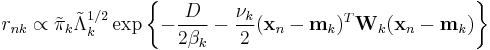
These can be converted from proportional to absolute values by normalizing over so that the corresponding values sum to 1.
Note that:
- The update equations for the parameters
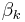 ,
, 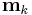 ,
, 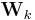 and
and 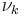 of the variables and depend on the statistics
of the variables and depend on the statistics 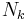 ,
, 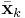 , and
, and 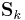 , and these statistics in turn depend on .
, and these statistics in turn depend on . - The update equations for the parameters
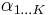 of the variable depend on the statistic , which depends in turn on .
of the variable depend on the statistic , which depends in turn on . - The update equation for has a direct circular dependence on , , and as well as an indirect circular dependence on , and through
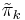 and
and 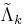 .
.
This suggests an iterative procedure that alternates between two steps:
- An E-step that computes the value of using the current values of all the other parameters.
- An M-step that uses the new value of to compute new values of all the other parameters.
Note that these steps correspond closely with the standard EM algorithm to derive a maximum likelihood or maximum a posteriori (MAP) solution for the parameters of a Gaussian mixture model. The responsibilities in the E step correspond closely to the posterior probabilities of the latent variables given the data, i.e. 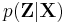 ; the computation of the statistics , , and corresponds closely to the computation of corresponding "soft-count" statistics over the data; and the use of those statistics to compute new values of the parameters corresponds closely to the use of soft counts to compute new parameter values in normal EM over a Gaussian mixture model.
; the computation of the statistics , , and corresponds closely to the computation of corresponding "soft-count" statistics over the data; and the use of those statistics to compute new values of the parameters corresponds closely to the use of soft counts to compute new parameter values in normal EM over a Gaussian mixture model.
Exponential-family distributions
Note that in the previous example, once the distribution over unobserved variables was assumed to factorize into distributions over the "parameters" and distributions over the "latent data", the derived "best" distribution for each variable was in the same family as the corresponding prior distribution over the variable. This is a general result that holds true for all prior distributions derived from the exponential family.
See also
- Variational message passing: a modular algorithm for variational Bayesian inference.
- Expectation-maximization algorithm: a related approach which corresponds to a special case of variational Bayesian inference.
Notes
- ^ Boyd, Stephen P.; Vandenberghe, Lieven (2004) (pdf). Convex Optimization. Cambridge University Press. ISBN 9780521833783. http://www.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf. Retrieved October 15, 2011.
- ^ Christopher Bishop, Pattern Recognition and Machine Learning, 2006
- ^ Based on Chapter 10 of Pattern Recognition and Machine Learning by Christopher M. Bishop
References
- Bishop, Christopher M. (2006). Pattern Recognition and Machine Learning. Springer. ISBN 0-387-31073-8.
External links
- Variational-Bayes Repository A repository of papers, software, and links related to the use of variational methods for approximate Bayesian learning
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay provides an introduction to variational methods (p. 422).
- Variational Algorithms for Approximate Bayesian Inference, by M. J. Beal includes comparisons of EM to Variational Bayesian EM and derivations of several models including Variational Bayesian HMMs.